

Was ist ein Data Warehouse? – Definition
Ein Data Warehouse ist ein zentraler Datenspeicher. Dort werden Daten aus verschiedenen Quellen gesammelt und für analytische Zwecke optimiert zur Verfügung stellt.
Der Begriff Data Warehouse wird auch synonym für das gesamte Data Warehouse System verwendet. Der Prozess des Bauens und Betreibens eines Data Warehouse wird auch als Data Warehousing bezeichnet.
Das Konzept des Data Warehousing wurde Ende der 1980er Jahre erstmalig populär. Es findet seit den 1990er Jahre bis heute eine breite Anwendung.
Ziele des Data Warehouse
Operative Systeme wie etwa ERP- (Enterprise Resource Planning) oder CRM- (Customer Relationship Management) Systeme und deren Datenmodelle sind optimiert für die Unterstützung von Kerngeschäftsprozessen.
Sie eignen sich allerdings nicht gut für analytische Zwecke. Zudem sind die Datenmodelle verschiedener Quellen nicht direkt verknüpfbar.
Das Ziel des Data Warehouse ist es, Daten aus verschiedenen Quellen zu integrieren und in einer für Analytics optimierten Form bereitzustellen. Dabei handelt es sich in der Regel um strukturierte Daten. Das Data Warehouse dient Nutzer:innen als zentrale Datenquelle für Auswertungen.
Es kann anhand von vier Merkmalen beschrieben werden:
- Daten sind themenorientiert aufbereitet.
- Daten sind integriert.
- Daten können im Zeitverlauf analysiert werden, sie werden zeitabhängig gespeichert.
- Daten werden gespeichert und dann nicht mehr geändert, sie sind nicht-volatil.
Funktionen des Data Warehouse
Was aber macht ein Data Warehouse? Wie funktioniert es? Im Data Warehouse System dreht sich alles um Daten und deren analytische Nutzung. Dafür muss es drei Funktionsbereiche abdecken (funktionale Architektur):

Im ersten Funktionsbereich werden Daten aus verschiedenen Quellen gesammelt. Das kann von der Quelle („push“-Prinzip) oder vom Data Warehouse („pull“-Prinzip) ausgehen. Dabei wird häufig eine Delta-Verarbeitung gewählt. Dabei werden nur Daten gesammelt, die sich seit dem letzten Datenaustausch verändert haben.
Im zweiten Funktionsbereich werden die gesammelten Daten geprüft, historisiert und für die Auswertung aufbereitet. Dazu gehört auch die Berechnung von Kennzahlen, beispielsweise für die Unternehmenssteuerung. Die Daten werden in einer Datenbank gespeichert, die im nächsten Schritt als Quelle für Analysen dient. Daher wird das Data Warehouse auch gerne als „single point of truth“ (SPoT) für Informationsbedürfnisse bezeichnet.
Im dritten Funktionsbereich finden Analysen statt. Diese fasst man unter dem Begriff Business Intelligence (BI) zusammen. BI Konsument:innen können mit Reports und Dashboards erfahren, was in ihrem Geschäftsbereich passiert ist. Um zu verstehen, warum etwas passiert ist, werden häufig dimensionale (auch OLAP = Online Analytical Processing genannt) und visuelle Analysen von Power Usern, Business oder Data Analyst:innen verwendet.
Architektur des Data Warehouse
Ein weiterer wichtiger Teil der Data Warehouse Architektur ist die Datenarchitektur. Die gängigste Form ist die sogenannte Hub & Spoke Architektur. Sie besteht aus drei Datenschichten.
Beim Sammeln der Daten werden sie zunächst in eine Art Parkplatz geschrieben, die sogenannte Staging Area. Diese ist in der Regel nur temporär vorhanden.
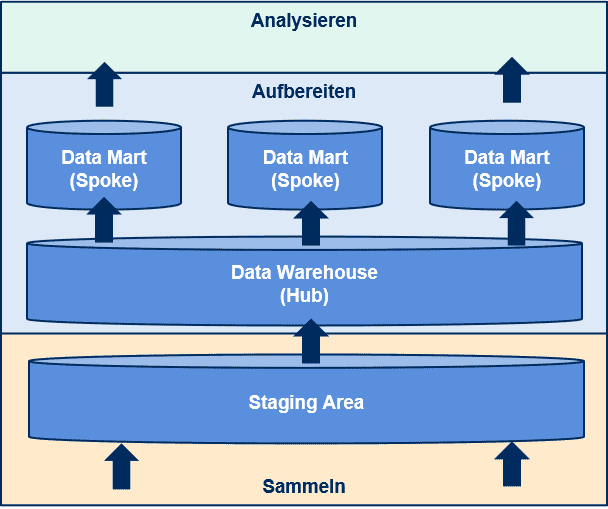
Die im zweiten Schritt aufbereiteten Daten werden dauerhaft gespeichert. Dabei wird unterschieden zwischen dem eigentlichen Data Warehouse und den Data Marts.
Das Data Warehouse enthält granulare und historisierte Geschäftsdaten, die in einem anwendungsunabhängigen Datenmodell gespeichert werden. Es soll damit für viele Anwendungsfälle als Datenquelle wiederverwendbar sein, daher der Name Hub.
Data Marts sind anwendungs- oder aufgabenspezifische Datenbestände, die meist Dimensionen und Kennzahlen enthalten. Diese Spokes werden aus dem Hub befüllt. Data Marts gelten vielfach als die Business Data Schicht, da die Dimensionen und Kennzahlen für Fachexpert:innen gut verständlich sind.
Die Datenmodellierung für Data Warehouses und Data Marts kann sehr aufwändig sein. Manche Unternehmen greifen daher auf sogenannte Referenzdatenmodelle zurück.
Das sind branchenspezifische Datenmodelle, die ähnlich wie Software lizenziert werden können. Man kann sie als Blaupause verstehen, die an die konkreten Anforderungen angepasst werden können. Durch die Nutzung eines Referenzdatenmodells verspricht man sich eine höhere Effizienz und Effektivität in der Data Warehouse Entwicklung.
Data Warehouse vs. Data Lake – ein Vergleich
Das Konzept des Data Warehouse findet seit rund 30 Jahren mehr oder weniger unverändert Anwendung. Manche finden es allerdings zu kompliziert und zu unflexibel.
Neue, auch semi- oder komplex strukturierte Daten wie Sensor-, Text- oder Bilddaten sollen mithilfe fortgeschrittener Analysemethoden wie Statistik und Künstliche Intelligenz analysiert werden können. Mit dieser explorativen BI möchten Data Scientists die Zukunft hervorsagen („was wird passieren“) und Handlungsempfehlungen („was soll ich tun“) ableiten, um die Geschäftsprozesse zu optimieren.
Dafür werden häufig Rohdaten benötigt. Die Data Warehouse Datenbank ist aber nur schlecht geeignet, um die großen Datenvolumen dieser Daten kosteneffizient zu speichern und zu verarbeiten. So entstand ab den 2000er Jahren das Konzept des Data Lakes. Dort werden Rohdaten in preisgünstigen und skalierfähigen Dateisystemen gespeichert.
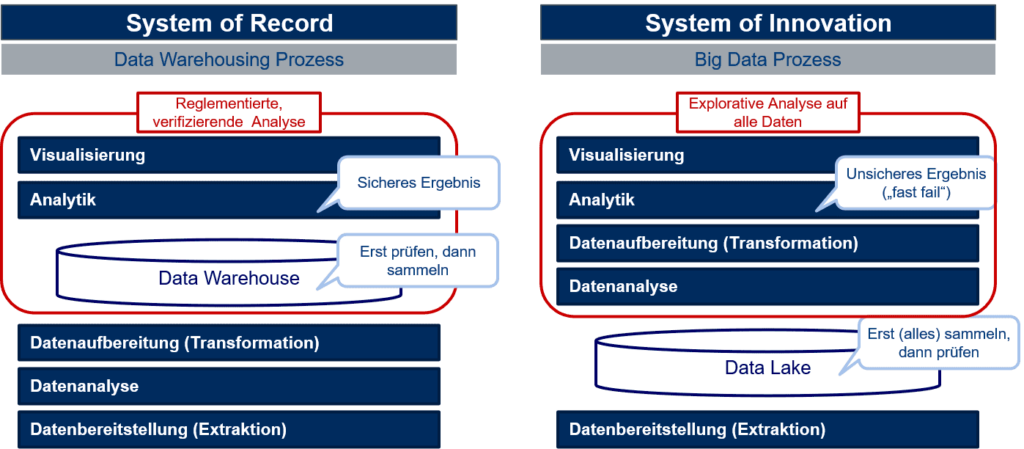
Der Data Lake kann das traditionelle Data Warehouse aber nicht ersetzen. Daher entstand das Konzept des Data Lakehouse. Hier werden beide Konzepte in einer Gesamtarchitektur genutzt. Häufig kommt dabei das Data Vault Prinzip zum Einsatz.
Die Diskussion um die richtige Datenarchitektur wird zunehmend durch die wachsende Verbreitung von Multi-/Hybrid-Cloud-Szenarien beeinflusst. Auch der Trend Data Mesh, ein eher organisatorisches Konzept, benötigt für die Umsetzung eine geeignete Plattform und Architektur.
Manche Unternehmen überlegen daher, ob das Konzept des Data Fabric eine Lösung für die Zukunft ist. Mit einer Data Fabric rückt man vom rein zentralistischen Prinzip des Data Warehouse, Data Lake und Data Lakehouse ab und wendet föderalistische Designprinzipien an, die eine verteilte Architektur unterstützen.
Was ist ein Data Warehouse System? Ein Überblick
Es gibt nicht eine einzige Data Warehouse Software. Vielmehr besteht ein Data Warehouse System aus verschiedenen Technologien, die ineinandergreifen.
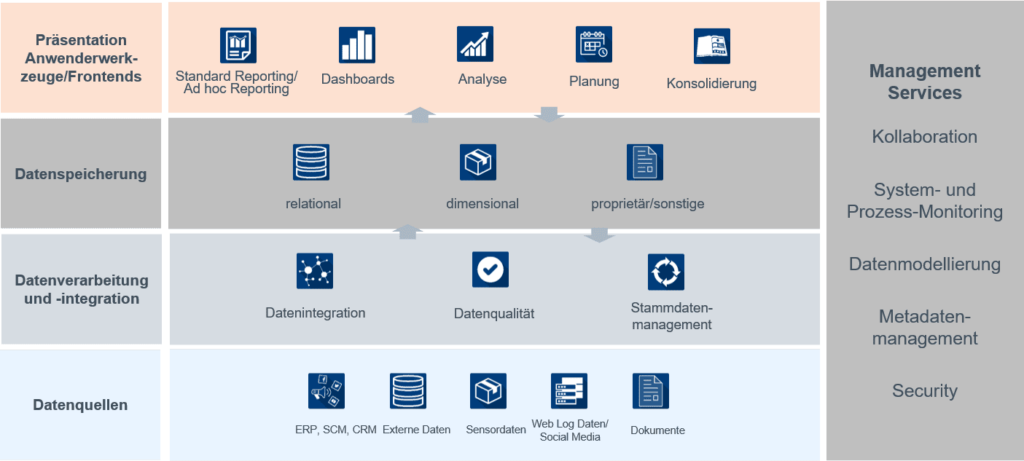
Für das Sammeln und Aufbereiten werden Data Pipelines entwickelt. Diese werden meist automatisiert betrieben. Dabei helfen häufig Datenintegrations-Plattformen, die manchmal als ETL- (extract transform load) oder ELT- (extract load transform) Werkzeuge bezeichnet werden.
Die Daten werden teils in Dateisystemen, teils in relationalen oder multidimensionalen Datenbanken gespeichert. Oft kommen Datenzugriff-Engines wie Data Virtualization Lösungen zum Einsatz.
Für die Analyse gibt es ebenfalls eine Vielzahl von Werkzeugen am Markt, die jeweils einen bestimmten funktionalen Fokus aufweisen, zum Beispiel Reporting/Dashboarding, klassische Analyse/OLAP, visuelle Analyse oder Advanced Analytics.
In dieser Hinsicht unterscheidet sich ein Data Lakehouse System nicht grundlegend vom Data Warehouse System. Es kommen im Data Lakehouse System aber häufig neuere, Open-Source-basierte und kommerzielle Technologien zum Einsatz. Das ist auch dadurch bedingt, dass ein Data Lakehouse häufig auf einer cloudbasierten Datenplattform umgesetzt wird.
In manchen Data Warehouse Systemen kommen auch Data Governance und Kollaborationslösungen zum Einsatz. Das kann unter anderem Software für einen Data Catalog, ein Metadaten Repository oder Datenqualitätsmanagement sein.
Ergänzende Tools helfen beim Data Warehouse Design (Modellierungswerkzeuge) oder garantieren den sicheren und verlässlichen Betrieb (System-, Prozessmonitoring oder Werkzeuge für Security).
Data Warehouse Beispiele
Der Markt der Data Warehouse Lösungen ist sehr groß. Für das Jahr 2021 schätzt BARC, dass auf dem deutschen Markt 415 Data Warehouse Anbieter mit 690 verschiedenen Data Warehouse Lösungen existieren.
Für viele Unternehmen ist es daher sehr schwierig, sich einen Überblick über diesen Softwaremarkt zu verschaffen. BARC unterstützt diese Unternehmen mit dem BARC Guide Data, BI & Analytics bei der ersten Orientierung und Sondierung. Der BARC Guide klassifiziert Lösungen nach dieser Matrix:
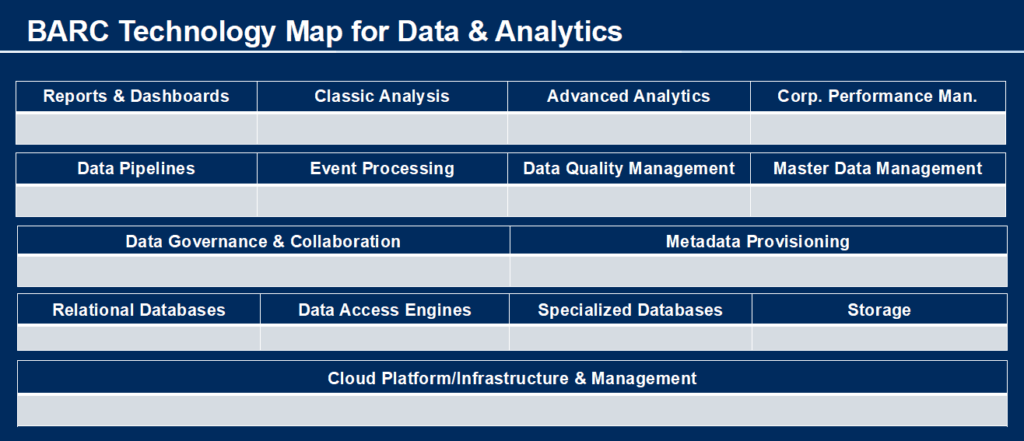
Weitere Informationen zu Data Warehouse Anbieter und Data Warehouse Beispielen finden sind in den BARC Scores sowie den BARC Surveys.














