

Teil 1: Testmethodik und Schwerpunkte
„Wir haben so viele Incidents in der Produktion, dass wir keine Zeit für ein effektives Testen unseres Data Warehouses finden“. So schilderte mir eine Teamleiterin ihre aktuelle Situation, ohne den Zusammenhang zwischen ungenügendem Testen und den Produktionsstörungen, die durch die unentdeckten Fehler verursacht wurden, wahrzunehmen. Ähnliche Situationen gibt es leider häufig. Da die besonderen Herausforderungen für das Testen von BI-Systemen und das mögliche Spektrum von Lösungen meist zu wenig bekannt sind, findet ein zielgerichtetes, effektives Testen oft nicht statt.
Besondere Herausforderungen beim Testen von analytischen Systemen
Durch die speziellen Eigenheiten von BI- und DWH-Systemen, ergeben sich einige Herausforderungen beim Testen dieser Systeme. Dazu nachfolgend einige Beispiele, wobei es sich hier jedoch nicht um eine vollständige Liste handelt:
- Datengetriebenes Testen anstelle von Usecases
In operativen Systemen ist das Testen nach Usecases üblich. Das bedeutet, ein Geschäftsvorfall wird durchgeführt und das Ergebnis einer einzelnen Transaktion als Abbildung in den Daten geprüft. Bei analytischen Systemen sind Usecases nicht vorhanden oder nur von untergeordneter Bedeutung. Im Vordergrund stehen datengetriebene Tests mit der Prüfung gesamter Datasets, was eine grundlegend andere Herangehensweise an die Erstellung von Testfällen nötig macht und teilweise identische Verfahren der Datenqualitätsprüfung verwendet. - Dynamische Code-Generierung durch Tools
In transaktionalen Systemen bleibt der Code unveränderlich, wie beispielsweise bei einem einmal geschriebenem SQL-Statement, eingebettet in den Code einer weiteren Programmiersprache. In analytischen Systemen wird der Code hingegen durch Frontend- oder ETL-Tools im Hintergrund generiert (vgl. Abbildung 1). Schon das Verändern einer Spaltenreihenfolge erzeugt eine neue SQL-Abfrage. Somit ist codebasiertes Testen nicht zweckmässig. Häufig ist der generierte Code zudem nicht ersichtlich, sodass hier Greybox-Tests erstellt und ausgeführt werden müssen.
| Transaktionale Systeme | Analytische Systeme |
| Testen nach Usecases | Datengetriebene Tests |
| Prüfen einzelner Datensätze | Prüfen gesamter Datasets |
| Statischer Code | Dynamisch generierter Code |
- Offizielle Normen und Standards berücksichtigen keine Eigenheiten von analytischen Systemen
Die üblichen Standards und Normen, wie etwa das V-Modell, sind für transaktionale Systeme angelegt. Ein Adaptieren auf BI- und DWH-Systeme ist nur mit dem notwendigen Transferaufwand und einigen Kompromissen möglich. - Herausforderungen durch agile Projektmethoden
Durch den Wechsel zu agilen Projektmethoden müssen Testvorbereitung und -durchführung in kürzeren Zeitfenstern erfolgen. Dadurch überfordert, wird häufig nur ungenügend getestet und die Softwarequalität verschlechtert sich. Dies müsste nicht sein, haben doch alle agilen Projektmethoden den Selbstanspruch, bessere Software in kürzerer Zeit bereitzustellen.
Lösungsoptionen
Durch eine angepasste Methodik ist ein effektives Testen von BI- und DWH-Systemen möglich. Auch dazu einige Beispiele:
- Vielseitigkeit der Testfälle
Leider wird vielfach nur auf funktionale Korrektheit getestet. Funktionale Vollständigkeit, wie das adäquate Reagieren auf alle attributbezogenen Wertebereiche in einem Ladeprozess, wird dagegen nur teilweise geprüft. Werden noch Kombinationen von unterschiedlichen Werten in mehreren Attributen geprüft, ist die Erstellung von Testfällen mittels Entscheidungstabellen sinnvoll.
Die Akzeptanzkriterien und -klassen nach ISO 25010 (vgl. folgende Abbildung, Download als pdf-Datei) bieten eine gute Orientierung, wenn nicht nur reine funktionale Tests erstellt und ausgeführt werden sollen. Daraus können deutlich vielseitigere Testfälle, wie etwa das Laufzeitverhalten von ETL-Prozessen (effiziente Performance: Zeitverhalten), Verhalten von ETL-Prozessen bei ungenügender Datenqualität in den Sourcedaten (Fehlertoleranz aus verlässlicher Software) oder Restart-Fähigkeit (Wiederherstellbarkeit), abgeleitet werden.
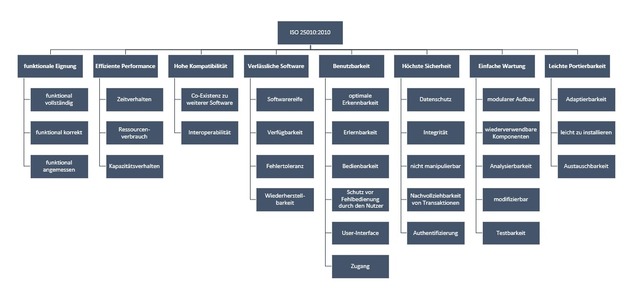
- Datengetriebene Tests
Auswertungen zeigen, dass mehr als die Hälfte der gefundenen Fehler in Data-Warehouse- und BI-Systemen auf die Daten zurückzuführen sind. Einerseits werden bei der Analyse oft nicht alle Wertebereiche und Kombinationen von Wertebereichen ermittelt, was zu unvollständigen Implementierungen führt. Andererseits kommt es durch Datenqualitätsprobleme aus den Quellsystemen immer wieder zu Störungen, beispielsweise zu Abbrüchen in den Ladeprozessen. - Testabdeckung
Da ein vollständiges Testen eines Systems nicht möglich ist und wirtschaftlich auch nicht sinnvoll wäre, bleibt die Frage, wann genügend getestet wurde. Ergänzend zur vorher beschriebenen Vielseitigkeit von Testfällen, ist dies nun eine quantitative Frage. Die notwendige Anzahl an Testfällen kann einfach Bottom-Up berechnet werden. Dabei wird zuerst die Komplexität und die Kritikalität der einzelnen Systemkomponenten ermittelt. Gerade die Business-Kritikalität, also die Bedeutung von analytischen Systemen, wird leider häufig unterschätzt, wodurch eine Systemarchitektur abgeleitet wird, die nicht der benötigten Verfügbarkeit entspricht.
In einem zweiten Schritt kann auf Basis der Komplexität eine Fehleranzahl angenommen werden (Verfahren «error guessing») und mit den entsprechenden Faktoren für die Testabdeckung zu Kritikalität und dem Verhältnis notwendiger Testfälle zum Entdecken eines Fehlers multipliziert werden.
Dieses Berechnungsverfahren ergibt häufig einen Testaufwand, der von denselben Personen als zu hoch kritisiert wird, die meistens auch den Vorwurf äußern, dass zu wenig getestet wurde. Der Testaufwand für Systeme lässt sich nur mittelfristig durch das Automatisieren von Regressionstests reduzieren. Bis dahin ist es Überzeugungsarbeit (schaffen von Awareness) oder das Eingehen von Kompromissen. - Kombination von agilen und traditionellen Testmethoden
Eine Effizienzsteigerung wird erreicht, indem die formalen Testfälle durch Review-Verfahren (statisches Testen) und agile Testmethoden ergänzt werden, beispielsweise nach dem Framework von Lisa Crispin und Janet Gregory. Zudem lohnt sich der Aufbau einer bewirtschafteten Regressionstestlibrary.
Summary
Grundvoraussetzung für ein effektives und genügendes methodisches Testen ist das Verständnis und die Kultur innerhalb des Unternehmens. Dies beginnt nicht zuletzt beim Management. Wird das Testen in erster Linie als Kostenfaktor wahrgenommen, wird vermutlich versucht werden, den Testaufwand möglichst gering zu halten. Eine echte Testkultur wird so jedoch nie entstehen.
Vielseitige und umfangreiche Testdaten sind eine elementare Voraussetzung für das Durchführen der Testfälle. Der Aspekt der zweckmässigen Testdaten wird im kommenden Teil 2 dieser Reihe beschrieben.
Teil 2: Testdaten-Management
Ungenügende Testdaten verhindern ein effektives Testen. Daher werden Fehler zu spät erkannt, manchmal erst in den produktiven Systemen. Vielfach können Fachanwender die korrekte Arbeitsweise eines Dashboards oder die Richtigkeit der Daten in einem Data Warehouse nur beurteilen, wenn diese möglichst realitätsnah sind. Aufgrund ihrer jahrelangen Erfahrung habe sie ein implizites Wissen entwickelt, um so intuitiv beurteilen zu können, ob die ausgewiesenen Beträge, Summen oder Mengen realistisch sind. Das heißt, sie erkennen dies aufgrund der Ihnen vertrauten Größenordnungen. In letzter Konsequenz bedeutet dies, dass produktive Daten für effektives Testen verwendet werden sollten. So zumindest die Forderung der Fachbereiche.
Die Verwendung von produktiven Daten ist jedoch aufgrund rechtlicher Anforderungen nicht uneingeschränkt möglich. Insbesondere die verschiedenen Datenschutzgesetze verlangen eine Zugriffsbeschränkung. Der Gesetzgeber unterscheidet nicht zwischen Produktions- und Testsystemen oder zwischen operativen und analytischen Systemen. Somit benötigen auch Testsysteme ein Berechtigungssystem, ergänzt mit Verfahren zum Maskieren der Daten (engl. Data Masking).
Anforderungen an Testdaten
Testdaten müssen verschiedene Anforderungen erfüllen, um für die unterschiedlichsten Testfälle geeignet zu sein:
- Möglichst vollständige Ausprägungen von Wertebereichen
Das bedeutet, dass die Daten folgende Anforderungen von Tests unterstützen:- Normalfälle
- Extrema (Ausreißer im gültigen Bereich wie Peaks)
- Sonderfälle, beispielsweise Sommer- oder Winterzeitwechsel in Zeitreihen
- Grenzwerte, um die korrekte Gruppenzuordnung testen zu können
- Fehlerhafte Daten für Negativtest
- Sich ändernde Daten um Mutationen (Change-Verhalten) oder das korrekte Abbilden von Historisierung (z.B. Slowly changing dimensions oder bitemporale Strukturen) zu prüfen
- Aktualität
Drei Jahre alte Testdaten bilden auch nur die Situation des Unternehmens vor drei Jahren ab. Aktuelle Informationen, wie organisatorische Anpassungen nach Reorganisationen oder neu eingeführte Produkte, fehlen. - Unterstützung aller Teststufen und -arten
Für das Testen von funktionaler Korrektheit und Vollständigkeit genügen meistens kleinere Mengen an Testdaten. Bei einem Lasttest (Performance) ist hingegen ein Vollbestand notwendig. Weitere unterschiedliche Anforderungen lassen sich aus den geplanten Positiv- oder Negativtests ableiten. Positivtests prüfen die korrekte Arbeitsweise eines Systems, meistens im Bereich Funktionalität oder Sicherheit. Negativtests prüfen das Verhalten des Systems außerhalb der gültigen Regeln, wozu auch die Robustheit eines Systems gehört. Beispielsweise wird geprüft, ob ein Ladeprozess in der Lage ist, fehlerhafte Daten zu erkennen und zurückzuweisen, oder ob diese trotzdem geladen werden oder ein Ladeprozess abstürzt. Die unterschiedlichen Anforderungen an Testverfahren lassen sich einfach aus der Norm ISO 25010 ableiten, die bereits in Teil 1 beschrieben wurde. - Möglichst realitätsnahe Daten
Die Überprüfung des Ergebnisses ist für jeden Tester bedeutend einfacher, wenn er mit vertrauten Daten arbeiten kann. Das bedeutet, dass realistische Stammdaten, wie Produktlisten, Preisstrukturen, Mengen, etc. verwendet werden sollten, was jedoch nicht gleichbedeutend mit operativen Produktionsdaten ist. Das Maskieren von Stammdaten ist somit nicht erforderlich. - Anonymisierung, wenn produktive, sensitive Daten eingesetzt werden (Masking)
Operative Produktionsdaten sollten nie unverändert bereitgestellt werden. Bei der Verwendung von personenbezogenen Daten ist das Anonymisieren oder das Beschränken des Zugriffs gemäß den verschiedenen Datenschutzgesetzen eine gesetzliche Vorgabe. Auch bei nicht personenbezogenen Daten sind mögliche Anforderungen an die Maskierung zu prüfen. Beispielsweise muss verhindert werden, dass bereits aus dem Testsystem das Unternehmensergebnis vorzeitig abgeleitet wird und eine Gewinnwarnung veröffentlicht oder Insiderhandel betrieben wird. Auf die verschiedenen Masking-Verfahren wird später in diesem Artikel noch genauer eingegangen. - Einfache und automatische Reproduzierbarkeit
Dies ist notwendig, um die Testumgebung periodisch mit neuen Testdaten zu befüllen, sei es teilweise oder bei einem vollständigen Aufbau. Das Reproduzieren bedeutet nicht, dass die Testdaten zu 100 % identisch mit der letzten Generierung sind, sie müssen nur die obigen Anforderungen erfüllen. - Unterschiedliche Attribut- und Dataset-Formate
So heterogen wie die System- und Datenlandschaft ist, so unterschiedlich sind auch die Testdaten. Das heißt, das Generieren von CSV-Files genügt nicht. Manchmal sind BLOB’s oder DB-spezifische Attribut-Formate oder Streaming-Daten notwendig. - DBMS und ETL-orientiert
Abhängig von den Tests werden Daten als Basis in einer Datenbank oder für einen Ladeprozess bereitgestellt. - Systemübergreifende Vollständigkeit
Üblicherweise bestehen Testumgebungen aus mehreren Applikationen und Datenbanken, die in den Testfällen in Kombination benötigt werden. So enthält eine Applikation die Auftragsdaten, die Produktedaten sind in einem Stammdatensystem und Kundendaten im CRM gespeichert. Tests können nur erfolgreich durchgeführt werden, wenn die zusammengehörenden Informationen in allen Systemen abgebildet sind.
Neben den oben beschriebenen Anforderungen gibt es noch weitere firmen- oder systemspezifische Anforderungen. Weitere Anforderungen werden aus einer erweiterten Datenbetrachtung abgeleitet, denn gerne wird vergessen, dass eine Systemumgebung nicht nur aus Daten mit Businessbezug, etwa transaktionale oder dimensionale Daten, besteht, sondern noch weitere Daten enthält, wie beispielsweise:
- Konfigurationsdaten (plattformspezifisch und unabhängig)
- Plattformspezifische Daten sind beispielsweise Servernamen, unabhängige sind generelle Systemeinstellungen, wie Tuning-Maßnahmen.
- Logdaten
- Metadaten
- Stammdaten
Durch die oben beschriebenen Anforderungen an Daten mit Businessbezug und zusätzlich die erweiterte Datenbetrachtung wird schnell eine Komplexität erreicht, die für den Aufbau und die Bewirtschaftung ein eigenes Subprojekt oder ein eigenes Testdaten-Management mit unterschiedlichen Rollen benötigt.
Synthetische oder produktive Daten?
In einem nächsten Schritt muss die Frage der Testdatenherkunft geklärt werden: Sollen produktive Daten verwendet werden? Oder müssen Testdaten erstellt werden – sogenannte synthetische Testdaten?
Das Verwenden von produktiven Daten ist tatsächlich weit verbreitet und auch zulässig, sofern gewisse Regeln berücksichtigt werden, wie das Maskieren von Daten aus bereits erwähnten Datenschutzgründen. Die Rahmenbedingungen für die Verwendung von produktiven Daten müssen vorgängig mit dem Data Owner und dem Datenschutzverantwortlichen geklärt werden.
Werden produktive Daten verwendet, hat dies den Vorteil, dass auf einfache Weise eine genügend große Anzahl von Datensätzen bereitgestellt werden kann, die außerdem noch die verschiedenen Ausprägungen abdecken, inklusive Probleme der Datenqualität. Allerdings werden nicht immer alle Datensätze benötigt. Eine Teilmenge (engl. Subset) ist häufig sinnvoller, insbesondere dann, wenn die Infrastruktur der Testumgebung kleiner dimensioniert ist als das Produktivsystem. Ansonsten sind unnötige Performance-Probleme wahrscheinlich. Auf das Thema Subsetting und mögliche Tools wird im dritten Teil dieser Artikelserie noch eingegangen.
Einfacher ist das Arbeiten mit synthetischen Daten, das heißt mit künstlich erzeugten Testdaten. Synthetische Daten eignen sich hervorragend für Negativtests, um die Robustheit und Fehlertoleranz eines Systems zu prüfen. Da synthetische Daten keinen Bezug zu realen Daten haben, sind auch keine rechtlichen Rahmenbedingungen einzuhalten. Jedoch ist die Erstellung einiges komplizierter, sollen doch sämtliche Wertebereiche und Kombinationen abgebildet werden. Zudem wird eine größere Anzahl von Datensätzen benötigt. Beide Anforderungen, Varianz und Volumen, werden nur mit einem Testdatengenerator erreicht. Das Generieren erfolgt üblicherweise aufgrund von Metadaten oder festen Wertelisten für Attributinhalte. Auf Grundlage der maximalen Anzahl an Ausprägungen je Attribut werden kartesische Produkte gebildet, die anschließend auf die Anzahl gewünschter Records reduziert werden. Die Toolgruppe der Testdatengeneratoren wird im dritten Teil dieser Artikelserie erklärt.
In der Praxis wird häufig ein hybrider Ansatz für die Erstellung von Testdaten gewählt. Für Normalfälle werden produktive, maskierte Daten verwendet und durch synthetische Testdaten für Negativtests ergänzt. Somit können sowohl Normalfälle als auch das Verhalten im Fehlerfall getestet werden.
Data Masking
Data Masking ist ein Oberbegriff für verschiedene Verfahren des Pseudoanonymisierens oder Anonymisierens, um Echtdaten so zu verändern, dass keine Rückschlüsse mehr auf die Originalwerte möglich sind. Die maskierten Daten sind jedoch trotzdem für die Durchführung von Tests geeignet. Data Masking ist nicht gleichbedeutend mit einem Berechtigungssystem, bei dem der der Zugriff bewusst eingeschränkt oder gar verhindert wird.
Bei den Verfahren des Pseudonymisierens werden Daten über eine Hilfstabelle oder einen speziellen Key oder Algorithmus umgeschlüsselt. Wer Zugriff auf diese Hilfstabelle oder den Key hat, oder den angewandten Algorithmus kennt, ist also in der Lage das Maskieren rückgängig zu machen.
Bei den Verfahren des Anonymisierens werden sensitive Daten mit verschiedenen technischen Verfahren dagegen so verschlüsselt, dass dies nicht mehr rückgängig gemacht werden kann, beispielsweise durch Hash-Algorithmen.
Data Masking muss verschiedene Prinzipien erfüllen:
- Masking darf nicht durch unbefugte Personen rückgängig gemacht werden können
- Gewährleisten der referentiellen Integrität
- Masking nur auf sensitiven Daten
- Repräsentatives Resultat nach Masking
- Wiederholbarkeit
- Einhaltung der Compliance-Vorgaben und der Datenschutzrichtlinien
Maskierungsverfahren werden nur auf einzelne Attribute, auf Attributgruppen oder auf Wertebereiche angewandt. Das Attributpaar Postleitzahlen und Ort ist ein Beispiel für Attributgruppen. Bei Wertebereichen sollten beispielsweise die Anzahl an Kunden oder das Umsatzvolumen in einem Marktgebiet weiterhin der Realität entsprechen.
Am Markt gibt es unterschiedliche Tools für Data Masking, die manchmal dreißig oder mehr Verfahren unterstützen. Je nach Hersteller werden diese Verfahren leider unterschiedlich benannt. Ein paar der üblichen Verfahren sind nachfolgend kurz erklärt:
- Scrumble
Scrumble schreddert Werte, indem zufällig neue Zeichen generiert werden. Bei der Anwendung von Scrumble sollte zumindest der Wertebereich definiert werden, beispielsweise ob und welche Sonderzeichen zulässig sind. Scrumble wird üblicherweise nur auf einzelne Attribute angewandt. Trotzdem führt Scrumble immer wieder zu Irritationen, beispielsweise wenn Namen nicht mehr aussprechbar sind, da nur noch eine zufällige Ansammlung von Konsonanten vorhanden ist. Daher ist Scrumble nur in Ausnahmefällen einzusetzen.
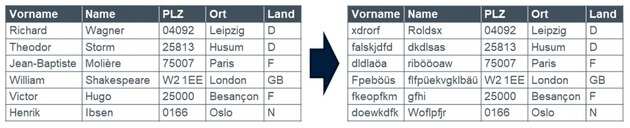
- Shuffle / Shuffling
Shuffle bedeutet mischen. Hier werden bestehende Werte durch einen Zufallsgenerator, meistens Hash, neu verteilt. Somit entstehen aus den bestehenden Werten, neue zufällige Kombination. Shuffle ist beim Maskieren von Personendaten ein beliebtes Verfahren für Name, Vorname und Adressattribute, wobei die Gruppe Postleitzahl und Ort unbedingt zusammengehalten werden muss.

- Substitution
Bei Substitution werden Werte innerhalb desselben Gültigkeitsbereich ersetzt. Das Verfahren wird beispielsweise auf Kreditkarten- oder Telefonnummern angewandt. - Reduction/Nulling
Nulling löscht den Inhalt eines Attributes ganz, Reduction nur einen Teil davon. bei Reduction wird in einer Telefonnummer noch die Länder- oder Regionen-Vorwahl stehen gelassen und nur der hintere Teil gelöscht. Ergebnis: +49-176- - Masking out Data/Replace Data
Bei diesem Verfahren wird ein Teil eines Wertes ersetzt. Dieses Verfahren ist bei Onlinestores zum teilweisen Anzeigen der in den Kunden- und Zahlungsdaten hinterlegten Kreditkartennummer beliebt. Beispiel: 5500 XXXX XXXX 5703

- Averaging
Averaging wird auf numerische Werte innerhalb einer Wertegruppe angewandt, wie Anzahl, Beträge oder Summen. Die Anzahl der bestellten Produkte oder Umsätze werden durch Zufallswerte ersetzt. Das Total einer Gruppe, beispielsweise eines Marktgebietes, soll dabei gleich groß bleiben. Beim Averaging sind zusätzliche Regeln sinnvoll, sodass es nicht zu seltsamen Größenverteilungen kommt, wie etwa dass ein Kunde 1 Mio. Umsatz gemacht hat und alle anderen nur noch Kleinstbeträge. Die Werte sollten außerdem in einer sinnvollen Relation stehen. Das bedeutet beispielsweise, dass die Bestellsumme realistisch in Bezug zur Anzahl bestellter Artikel und Listenpreise ist. Auch sollten Rabatte in einem realistischen Rahmen stehen. Averaging zeigt, dass das Maskieren von numerischen Werten deutlich komplexer ist.
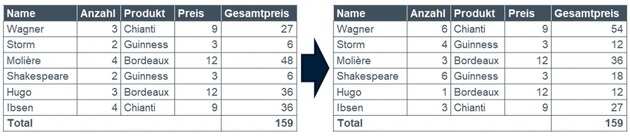
Neben den oben beschriebenen Verfahren, gibt es noch verschiedene weitere Möglichkeiten des Data Masking. Einige davon sind nur Abwandlungen der oben beschriebenen Verfahren. Gerade zu Averaging gibt es eine Vielzahl an Subvarianten mit den unterschiedlichsten Bezeichnungen.
Summary
Das Bereitstellen und Aktualisieren der Testdaten in einer Testumgebung ist eine zeitintensive Aufgabe, verbunden mit einem hohen Abstimmungsaufwand. Einerseits gibt es die Erwartung, dass laufende Tests zu Ende geführt und Fehler analysiert werden können. Auf der anderen Seite steht die Erwartung, dass die Testdaten eine genügende Qualität haben und nicht zu unerwünschten Störungen des Testbetriebs führen. Diese beiden Erwartungen stehen häufig in Widerspruch. Eine klare Kommunikation über den Betrieb der Testumgebungen und die Aktualisierung der Testdaten ist somit notwendig.
Nach Abschluss eines Testbetriebs muss entschieden werden, was mit den Testdaten geschieht. Können diese einfach gelöscht werden? Oder gibt es eine Nachweispflicht zu den Testergebnissen aus regulatorischen Gründen? Möglicherweise müssen Testfälle und die dazugehörenden Testdaten archiviert werden.
Ein effektives Testdaten-Management ist eine komplexe Aufgabe, die nur mittels Automatisierung effizient gelöst werden kann. Die Möglichkeiten der Automatisierung und der dazu geeigneten Tools wird im dritten Teil dieser Artikelserie beschrieben.
Teil 3: Testautomatisierung und -tools
Testen ist eine oft unbeliebte Aufgabe und wird als mühsam und aufwändig empfunden. Daher äußern viele den Wunsch, mittels Automatisierung effizienter zu werden und Aufgaben vom Menschen auf die Maschine zu übertragen. Die zentrale Voraussetzung für Automatisieren sind repetitive Tätigkeiten, das heißt, es muss ein Skaleneffekt über die Zeitachse oder die Masse möglich sein.
Skaleneffekte über die Zeitachse bedeutet, dass der gleiche Test oder die gleiche Aktivität in regelmäßigen zeitlichen Abständen wiederholt wird. Dies trifft etwa auf Regressionstests und Datenqualitätsprüfungen zu. Ähnliche Skaleneffekte werden ebenfalls bei der Bereitstellung von Testdaten erreicht.
Skaleneffekte über die Masse bedeutet, dass ähnliche oder gleiche Aktivitäten parallel ausgeführt werden. Beispiele sind Benutzbarkeitstests oder Funktionstests, die dynamisch über eine Kombination von Parametern gesteuert werden, wie entscheidungstabellen-gesteuerte funktionale Tests. Auch das Generieren einer größeren Menge von synthetischen Testdaten ist ein weiteres Beispiel dafür.
Es wird leider nie möglich sein, sämtliche Testfälle zu den Akzeptanzkriterien nach ISO 25010 zu automatisieren (siehe dazu Teil 1 dieser Artikelserie). Keine Automatisierungsmöglichkeiten gibt es bei Tests der Benutzerakzeptanz und -zufriedenheit, Konzepten und Handbüchern, oder bei ersten funktionalen Tests eines neugeschriebenen Moduls.
Testautomatisierung wird den Menschen zudem nie komplett ersetzen. Vielmehr wird der Mensch von einem ausführenden zu einem hauptsächlich kontrollierenden und korrigierenden Faktor. Eine effiziente Automatisierung ist nur mittels Standardisierung, also der Eliminierung von unnötiger Varianz und einem konsequenten und zweckmässigen Tooleinsatz, abgestimmt und koordiniert durch das Testmanagement, möglich.
Anstelle von Tools gibt es die Möglichkeit vereinfachter Formen der Automatisierung. Dazu gehören Scripts, Templates und Checklisten. Eigenentwickelte Scripts und Queries können bei den Verfahren Baseline- und Dualstream-Tests eingesetzt werden oder bei selbstentwickelten Komparatoren mittels SQL MINUS. Diese Verfahren werden detailliert im Seminar «Testen von DWH- und BI-Systemen» erklärt.
Templates unterstützen die Erstellung von Testfall- oder Fehlerbeschreibungen, oder Testkonzepten. Der Automatisierungsgrad ist jedoch hier relativ gering, da durch Dokumentenvorlagen nur die Struktur vereinheitlicht, die Vollständigkeit sichergestellt und die Verständlichkeit für den Leser durch Einheitlichkeit erreicht wird. Gute Dokumentenvorlagen für das Testen liefert die Norm IEEE 829, in der Versionen 1998 und 2008 oder neu auch Teil 3 von ISO 29119.
Checklisten hingegen automatisieren das repetitive Abarbeiten von immer gleichen Prüfungen. Checklisten sind geeignet für das Überprüfen des Designs von Reports oder Dashboards. Templates und Checklisten werden ebenfalls eingehend im zweitägigen Seminar «Testen von DWH- und BI-Systemen» erklärt.
Art der wiederholten Ausführung
Automatisieren lassen sich nur Testfälle, die wiederholt ausgeführt werden. Dies klingt zunächst nach einer Binsenwahrheit. Bei genauerer Betrachtung gibt es unterschiedliche Arten von Wiederholung:
- Zeitliche Wiederholung
Zu bestimmten Zeitpunkten wird ein Set von Testfällen ausgeführt, beispielsweise eine Gruppe von Regressionstests am Ende einer Projektphase oder bei einem Releasewechsel. - Situative Wiederholung
Die Ausführung dieser Wiederholung erfolgt auf Basis von Einzelentscheidungen. Dazu gehören etwa kleinere Test-Sets für einen Modultest, welche durch den Entwickler angestoßen werden, um Funktionen nach Änderungen zu überprüfen. Zur situativen Wiederholung zählt auch das Ausführen eines Test-Sets zur spezifischen Fehlersuche, beispielsweise wenn eine produktive Störung aufgrund eines nicht entdeckten Fehlers auftritt. - Permanente Wiederholung
Das Monitoring der Datenqualität ist eine Daueraufgabe und somit ein Beispiel für permanente Wiederholung. Die Prüfungen basieren nicht selten auf datengetriebenen Tests, die operationalisiert wurden und nun Teil des produktiven Monitorings sind. - Parallele Ausführung
Die parallele Ausführung ist keine Wiederholung im klassischen Sinn. Hier werden die gleichen Testfälle mehrfach gleichzeitig ausgeführt, um Last auf dem System zu erzeugen und Performance-Tests durchführen zu können.
Zu bestimmten Zeitpunkten wird ein Set von Testfällen ausgeführt, beispielsweise eine Gruppe von Regressionstests am Ende einer Projektphase oder bei einem Releasewechsel.
Overview verschiedener Toolklassen
Am Markt gibt es eine große Anzahl von teilweise recht unbekannten Tools, die verschiedene Aufgaben des Testens unterstützen. Einige Lösungen sind Open Source, erstellt von Entwicklern, die aus der Not heraus eigene Lösungen für die Testautomatisierung erstellten.
Nachfolgend sind nur die Toolklassen beschrieben, die in der Toolübersicht dieses Artikels vorkommen. Es gibt weitere, hier nicht beschriebene Toolklassen, wie Debugger für die Fehlersuche. Debugger können zusätzlich für die funktionale Prüfungen des Codes eingesetzt werden, anstelle von Walkthroughs. Somit können statische Tests durch dynamische Whitebox-Tests ersetzt werden.
- Test Suiten
Test Suiten beinhalten verschiedene Funktionen zur Unterstützung des Testmanagements, wie Testfall- und Fehler-Tracking, automatisierte Ausführung von Testfällen, Komparatoren und teilweise auch Testdaten-Management. - Tracking von Testfällen oder Fehlern
Tracking-Tools verwalten Testfälle (engl. test cases) oder Fehler (engl. defects). Im Detail speichern sie die Testfallbeschreibung, ergänzende Informationen, wie Handlungsanweisungen oder Testdaten und den aktuellen Status. Ein integriertes Reporting ermöglicht jederzeit eine Gesamtübersicht zur Unterstützung des Testmanagements. Tracking-Tools ermöglichen eine detaillierte Fehlerdokumentation, beispielsweise mittels Screenshots, und eine Fehlerklassifikation. Tracking-Funktionen sind ein zentrales Element von Test Suiten. Weitere beliebte Tracking-Tools sind Jira oder Sharepoint. - Automatisierung
Automatisierungstools können weiter unterteilt werden in das Automatisieren von Datenqualitätsprüfungen und in Software-Tests. Für die Datenqualitätsprüfung können auch klassische Datenqualitätstools eingesetzt werden, wie SAS Data Quality oder Attacama. Eine weitere Möglichkeit der Überprüfung der Datenqualität bieten ausgereifte ETL-Suiten, wie Informatica Power Center oder IBM Data Stage.
Viele Lösungen der Gruppe der Software-Test-Tools ermöglicht die automatisierte Ausführung von funktionalen Tests, wie sie bei Regressionstest verwendet werden. Eine interessante Gruppe der Software-Test-Tools sind Lösungen für Lasttests. Sie können Benutzeraktivitäten simulieren oder I/O auf Datenquellen. - Subsetting
Es ist nicht immer sinnvoll den vollen produktiven Datenbestand für das Testen zu verwenden, insbesondere dann, wenn die Testumgebung kleiner dimensioniert ist. Unnötige Performance-Probleme sind sonst die Folge. Benötigt werden Testdaten mit der benötigten Varianz und einer Vollständigkeit über alle Applikationen. Das heißt, Vielseitigkeit und Konsistenz der Testdaten ist gefordert. Dazu sind komplexe Regeln zur Selektion notwendig, die häufig nur toolbasiert verwaltet und periodisch ausgeführt werden können.
Für Performance-Tests ist Subsetting nicht sinnvoll. Hier wird fast immer ein Vollbestand und eine Testumgebung benötigt, die von der Dimensionierung (Sizing) identisch ist mit der Produktivumgebung.
Der Einsatz von Subsetting-Tools sollte immer durch Data Masking-Tools ergänzt werden. - Data Masking
Tools dieser Kategorie anonymisieren oder pseudonymisieren produktive Daten mittels verschiedener Verfahren. Ausgereifte Tools unterstützen üblicherweise über 20 verschiedene Verfahren, wobei verschiedene Varianten von Shuffle, Reduction, Nulling und Averaging die Häufigsten sind (Siehe dazu Teil 2 dieser Artikelserie). - Generator für Testdaten
Für das Testen von Data-Warehouse- und Business-Intelligence-Systemen sind üblicherweise größere Datenmengen notwendig. Dies übersteigt häufig die Möglichkeiten einer manuellen Testdatenerstellung oder sie ist wirtschaftlich nicht sinnvoll. Testdaten-Generatoren hingegen sind in der Lage Millionen von Datensätzen zu erstellen.
Bei der Evaluation eines Testdaten-Generators sind zwei Faktoren wichtig: Die Möglichkeit der Parametrisierung von Wertebereichen und Inhalten und die Output-Formate. - Infrastruktur Management
Diese Toolkategorie ermöglicht den effizienten Betrieb einer Testumgebung. Im weiteren Sinne zählen dazu auch Werkzeuge zur Paketierung, Versionierung und Übertragung zwischen den verschiedenen Umgebungen. Weitere Tools übernehmen spezialisierte Aufgaben, wie etwa TimeShiftX, welches das Verändern der Systemzeit in einer gesamten Umgebung ermöglicht und somit zeitabhänge Tests, wie die Umstellung auf Sommer- oder Winterzeit, zulässt.
Tool-Übersicht
Die nachfolgende Liste ist nur ein kurzer Auszug möglicher Tools. Bewusst nicht aufgeführt wurden Tools, die ausschließlich für die eigene Infrastruktur des Herstellers geeignet sind, wie herstellerspezifische Lösungen von Microsoft oder SAP. Eine ausführliche Liste mit weiteren Lösungen und detaillierten Beschreibungen ist vorhanden.
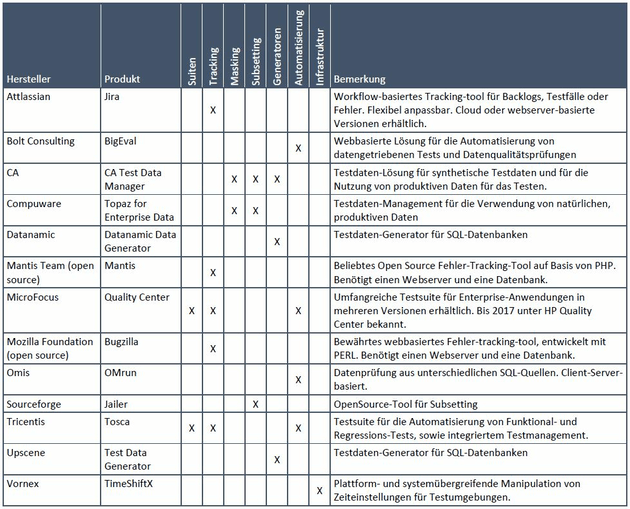
Summary
Durch den Einsatz von Tools wird das Testen nicht automatisch verbessert. Toolgläubigkeit ist hier fehl am Platz. Zu viele Tools sind sogar eher kontraproduktiv, da der Unterhalt der Tools und der Lernaufwand im Verhältnis zum Nutzen nicht wirtschaftlich sind. Gerade bei selten genutzten Tools kommt es immer wieder zu Bedienfehlern und zu Schwierigkeiten bei der Anwendung. Eine sinnvolle Lernkurve wird nicht erreicht.
Testautomatisierung als Teil des Testmanagements ist somit zuerst eine konzeptionelle Arbeit mit der Identifikation von Automatisierungspotentialen. Erst anschließend erfolgt eine Toolevaluation. Das wichtigste Tool im Testen bleibt weiterhin das menschliche Hirn.
Die BARC unterstützt Sie gerne bei Ihren Herausforderungen im Testen, wie Aufbau von Regressionstests, Erweiterung der Testmethodik und des Testdatenmanagements oder der Testtool-Evaluation. Wir verfügen ebenfalls über Erfahrung im agilen Testen oder der Ermittlung einer zweckmäßigen Testabdeckung. Gerne können Sie uns dazu kontaktieren.
Somit sind wir am Schluss der dreiteiligen Serie zum Testen angekommen. Ich wünsche Ihnen nun viel Erfolg beim zukünftigen Testen,
Herbert Stauffer














