

Am 22.04.2020 führten wir mit knapp 300 Teilnehmer:innen live das Webinar „Die vier heißesten Data-Cataloging-Anbieter im Vergleich“ durch. Das spezielle Webinar-Format schafft einen Rahmen, in dem mehrere Anbieter in kurzer Zeit direkt nacheinander ihre Lösung live in einer Demo präsentieren dürfen.
Damit die Präsentationen für den/die Zuschauer:in vergleichbar sind, startete das Webinar mit einer Einleitung durch BARC und der Vorstellung einer Aufgabenstellung für die Anbieter.
Die Zuhörer:innen haben im Webinar die Rolle des Kernteams übernommen und die Werkzeuge nach dem Pitch live bewertet. Für mehr Interaktivität haben wir neben einem Q&A auch einen kleinen Proof of Concept (PoC) gestaltet. Insgesamt kamen das Format und die Inhalte sehr gut an, wie an dem Live-Feedback: zu erkennen ist.

Sie möchten sich das Webinar in voller Länge ansehen? Hier gelangen Sie zur Aufzeichnung.
Unsere Shortlist
Bei BARC zählen wir derzeit mindestens 90 Hersteller mit Lösungen im Bereich Data Cataloging. Die Erstellung unserer Shortlist im Vorfeld des Webinars war daher nicht trivial. Die Data-Cataloging-Produkte lassen sich unterschiedlichen Segmenten zuordnen. Die Segmente weisen in der Regel besondere Charakteristika auf. Die drei Hauptgruppen bilden dabei:
- Datenkatalog-Spezialisten
- Datenkataloge als Funktion in einer speziellen Anwendungsumgebung bspw. für Advanced Analytics, Data Preparation, Visual Analytics oder BI
- Datenkatalog als Werkzeug, Funktion oder eng integriert in Plattformen für Data Governance und / oder Datenmanagement
Aus diesen Segmenten haben wir die aus unserer Sicht heißesten Werkzeuge für Data Cataloging ausgesucht:
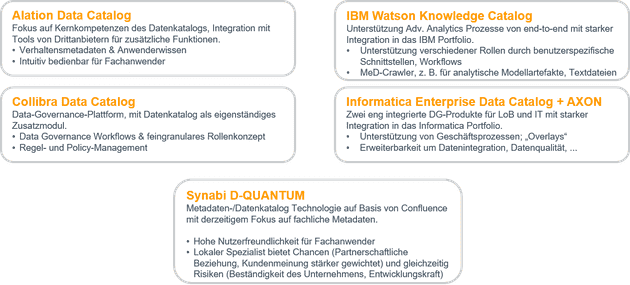
- Alation: Data Catalog als Spezialist
- Collibra: Data Catalog als zusätzliche Applikation auf Basis der Collibra Data Governance Lösung
- IBM: Watson Knowledge Catalog in seiner seit September 2019 neuen Version aus der Zusammenführung aus dem Information Governance Catalog und dem Watson Knowledge Catalog
- Informatica: Enterprise Data Catalog und AXON Data Governance, die vor allem Cataloging-Funktionen im Data-Governance-Kontext anbieten
BARC hat die Shortlist aus der Marktnachfrage (Relevanz in Kundenprojekten, Sichtbarkeit auf Events) sowie aus eigenen Evaluierungen der Werkzeuge abgeleitet. Leider war es Alation nicht möglich, am Webinar teilzunehmen. In der Vorbereitung auf das Webinar war Alation noch im Ausbau seiner deutschsprachigen Präsenz und hat daher die Teilnahme mangels fehlendem deutschen Sprecher abgesagt.
Das hat uns dazu bewogen, einen Raum für einen interessanten lokalen Data-Governance-Spezialisten zu schaffen, der sich dem Thema Data Cataloging fachlich nähert: Synabi.
Im Vorfeld der Produktdemonstrationen habe ich eine kurze Einschätzung zu den Anbietern gegeben. Dabei habe ich mir persönlich die Frage gestellt: „Welche zwei Dinge fallen mir als erstes ein, wenn ich an diese Lösung denke?“. Diese Art der Aufgabenstellung sollte dazu dienen, den besonderen Charakter der Werkzeuge kenntlich zu machen und die Werkzeuge voneinander abzugrenzen.
In der groben Betrachtung von Funktionen selbst würden wir kaum Unterschiede bei den großen Anbietern bemerken. Der Teufel liegt bekanntlich im Detail oder aber eben im Sweetspot der Werkzeuge. Das zeigen auch die Erkenntnisse aus den Diskussionen in unseren Seminaren zu „Das 1×1 des Data Cataloging“, das wir als eintägiges Seminar oder als Workshop zur Beantwortung individueller Fragen anbieten.
Aufgabenstellung
Für die Bewertung durch die Teilnehmer:innen im Webinar haben wir folgende Rahmenbedingungen geschaffen, um ein Data-Cataloging-Werkzeug auszuwählen, das unsere Business Analysen, Data Scientists und Data Engineers im Kontext von Advanced Analytics unterstützt:

Wir haben uns in die Rollen hinein versetzt und den Anbietern folgende Fragestellungen für die Präsentation vorgegeben:
Wir suchen nach einem Datenkatalog, der…
- Connect & Crawl: Welche Mechanismen und Automatismen vereinfachen den Import von Metadaten? Welche Arten von Datenquellen werden unterstützt? Wie kann ML helfen?
- Curate: Welche Mechanismen und Automatismen vereinfachen die Pflege von Metadaten und unterstützen die Akteure bei der Katalogisierung, Verknüpfung, Anreicherung und Qualitätssicherung von Daten? Welche „Metadaten“ für ein Datenobjekt werden unterstützt? Welche Konzepte werden unterstützt, um den Datenkatalog zum Leben zu erwecken? Welchen Mehrwert haben diese Nutzer:innen durch die Nutzung des Produkts? Wie kann ML helfen?
- Consume: Welche Funktionen unterstützen die Akteure bei der Suche nach den richtigen Daten für ihre Arbeit? Welche Funktionen werden angeboten, um Transparenz über Daten, Analyse und Nutzung zu erhalten? Welche Funktionen werden angeboten, um auf Daten zuzugreifen? Welchen Mehrwert haben diese Nutzer:innen durch die Nutzung des Produkts? Wie kann ML helfen?
- Collaborate: Inwieweit wird Zusammenarbeit unterstützt, um a) die Zusammenarbeit verschiedener Rollen zu ermöglichen, b) die Pflege und Nutzung von Datenbeständen zu unterstützen?
Jeder der vier Anbieter hatte 20 Minuten Zeit, um die Fragen anhand einer Live-Demo zu beantworten. Im Anschluss stellten sich die Anbieter fünf Minuten den Fragen des Publikums bzw. Kernteams. Alle Anbieter meisterten die Herausforderung, in so kurzer Zeit die wesentlichen Sachverhalte ihrer Lösung vorzustellen.
Das heißeste Data-Cataloging-Werkzeug: Wie haben die Teilnehmer:innen abgestimmt?
Nach der Präsentation kam ein Audience-Response-System zum Einsatz. Die Zuhörer:innen bewerteten die Anbieter direkt im Anschluss in den drei Kategorien „Curate“, „Consume“ und „Collaborate“.
Abgestimmt haben sowohl Anwenderunternehmen als auch die Anbieter selbst, die in unterschiedlicher Anzahl im Webinar vertreten waren.
Mindestens 130 Teilnehmer:innen votierten dabei Collibra auf den ersten Platz in allen Kategorien. Den letzten Platz belegte durchweg Synabi. Das Ergebnis verwundert nicht, da Synabi sicher nicht die funktionale Breite der anderen Lösungen abdeckt, sondern vielmehr speziellere Kundenszenarien erfüllt. Die Plätze zwei und drei teilten sich IBM und Informatica im Wechsel mit minimalen Abweichungen.
Es sei hier nochmals darauf hingewiesen, dass die Hersteller innerhalb kürzester Zeit versucht haben, die Vorzüge ihrer Produkte zu zeigen. Das ist eine Herausforderung. Danke an dieser Stelle, das haben alle Moderatoren wirklich prima gemacht!
Was wir in der Folge an Grafiken sehen, ist der Eindruck der Teilnehmer:innen, den die Präsentation hinterlassen hat. Unter den Zuhörer:innenn waren auch Mitarbeiter:innen der jeweiligen Hersteller. Daher sind die Ergebnisse ein Indiz für die Leistungsfähigkeit der Software. Sie ersetzen aber keineswegs eine gründliche Marktsondierung und Produkttests.
Aufgrund der knappen Zeit haben sich die Hersteller nur auf ausgewählte Aspekte konzentrieren können. Daher möchte ich in der Folge meine Eindrücke aus zwei Sichtweisen geben, die sich ausschließlich auf das im Webinar Gezeigte beziehen: Zum einen mein Eindruck zur Präsentation, zum anderen die gezeigten funktionalen Highlights der Lösungen.
Mein Eindruck zur Präsentation im Allgemeinen
Mein Eindruck zu den Präsentationen war, dass vor allem Collibra es geschafft hat, seine „Story“ anschaulich und nachvollziehbar zu präsentieren. Mir ist besonders aufgefallen, dass das Verständnis für das Werkzeug durch die Nutzung eines realen, nachvollziehbaren Prozesses besser vermittelt werden konnte. Es herrschte zu jeder Zeit Transparenz darüber, wo ich mich im Prozess und im Werkzeug befinde.
Collibra hat dabei nicht versucht, alle Funktionen zu zeigen, sondern eine nachvollziehbare Lösung der Aufgabenstellung präsentiert. Meiner Überzeugung nach haben die Zuschauer:innen vor allem auch dies als gelungen empfunden und Collibra in der nachfolgenden Evaluierung honoriert.
Zuhörerfrage: Wie funktioniert die Bereitstellung eines Data Sets in Collibra? Wird wirklich eine Datei bereitgestellt oder wird ein Workflow zur Freigabe angestoßen?
Antwort von Collibra: Die direkte Bereitstellung des Datensatzes ist das Zielbild hinter der in der Demonstration skizzierten Journey. Zum jetzigen Zeitpunkt wird am Ende des Freigabe-Prozesses ein externer Workflow zur Bereitstellung (z. B. über ein Jira- oder ServiceNow-Ticket; bzw. über Identity Access Management) angestoßen.
Die Präsentation von Informatica war gut und umfassend, aber ich habe diese als sehr funktional empfunden. Zwar wurde die Lösung auch anhand eines Prozesses gezeigt, der Fokus lag meiner Ansicht nach jedoch eher im Aufzeigen der zahlreichen Funktionen der Informatica-Produkte. So wurde die Zeit knapp, um die wesentlichen Funktionen für die Aufgabenstellung zu zeigen.
Dadurch wurde es schwer, dem Faden zu folgen. Im Endeffekt blieb bei mir der Eindruck eines sehr reichhaltigen funktionalen Baukastens statt einer Lösung für unsere Aufgabenstellung. Eine Ausnahme gab es dabei: Informatica stellte als einziger Anbieter einen SAP BW Adapter vor, der in der Lage ist, Metadaten zu SAP-Objekten wie auch „Queries“ auszulesen.
Zuhörerfrage: Ich sehe bei Informatica 2 getrennte Werkzeuge. Wie sind die technischen Metadaten im Catalog mit den fachlichen Beschreibungen in Axon integriert (beide Richtungen, automatisierte Synchronisierung)?
Antwort von Informatica: Die Verknüpfung erfolgt über Business Terms, die auch mit AI/ML Unterstützung den technischen Assets zugewiesen werden können. Werden dann z. B. Änderungen in Axon an der Beschreibung vorgenommen, wird automatisch die Beschreibung im EDC aktualisiert. Ebenso können in Axon Business Terms mit den entsprechenden technischen Metadaten verknüpft werden und man kann dann von Axon direkt auch in den EDC springen. Werden dann im EDC Aktualisierungen vorgenommen, werden diese automatisch in Axon aktualisiert.
IBM präsentierte seinen Datenkatalog als Teil des Cloud Pak for Data neben anderen Services. IBM zeigte damit einen anderen Ansatz, in dem der Kuratierung von Daten eine besondere Bedeutung zukommt. Diese findet nicht direkt im Datenkatalog statt, sondern ist Teil des Datenintegrations- und Datenaufbereitungsprozesses. Der eigentliche Katalog dient als Werkzeug für die Suche und Navigation in den Metadaten, die in dem Aufbereitungsprozess dediziert erhoben werden.
IBM fokussierte sich auf funktionale Highlights und verwies des Öfteren auf die entsprechenden Punkte in der Aufgabenstellung. Das half zur Orientierung. Aber letztendlich blieb auch hier der Eindruck, dass 20 Minuten bei weitem nicht ausreichen, die Plattform verstehen zu können.
Zuhörerfrage: Wie ist das Zusammenspiel mit dem IBM InfoSphere Information Governance Catalog? Sind die Lösungen komplementär oder überlappen sich beide Lösungen? Falls sie komplementär sind, sind sie kombinierbar und wenn ja, was ist der „value-added“ der InfoSphere Lösung?
Antwort von IBM: Der IBM InfoSphere Information Governance Catalog (IGC) wurde mit dem früheren IBM Watson Knowledge Catalog (WKC) integriert, diese kombinierte Lösung heißt wieder WKC und wurde in der Demo gezeigt. Die Lösungen sind also kombinierbar und in der gezeigten Version auch schon technisch kombiniert. Der Added Value ist die Kombination der IGC und der früheren WKC Funktionen in einem Produkt (wie in der Demo gezeigt).
Den Abschluss bildete Synabi als lokaler Spezialist. Als neuer Kandidat nutzte Synabi die Chance, sich und seine Philosophie ausführlicher darzustellen, bevor es in den Demo-Teil ging. Im Demo-Teil konnte ein guter Eindruck der Software und dessen Handhabung vermittelt werden. Der Bezug zur Aufgabenstellung Advanced Analytics wurde mir persönlich nicht klar kommuniziert und meiner Vorstellungskraft überlassen.
Auffällig war hier der Fokus auf die fachlichen Nutzer. Nach der Vorstellung der führenden Lösungen hat sich die funktionale Differenz zu dem Spezialisten deutlich gezeigt, der seine Lösung nach Kundenbedarfen ausbaut.
Zuhörerfrage: Welche Vorteile hat man, wenn man schon Confluence als Intranet als Lösung im Einsatz hat?
Antwort von Synabi: Die Nutzer haben ein gewohntes Interface, sodass die Lösung schneller und besser angenommen wird.
Mein Eindruck zu den gezeigten funktionalen Highlights
Gerne möchte ich meine Eindrücke zu den gezeigten Funktionen in den Aufgabenstellungen mit Ihnen teilen. Dabei beziehe ich mich auf das Gezeigte und versuche damit dem Urteil der Zuhörer einige zusätzliche Informationen hinzuzufügen.
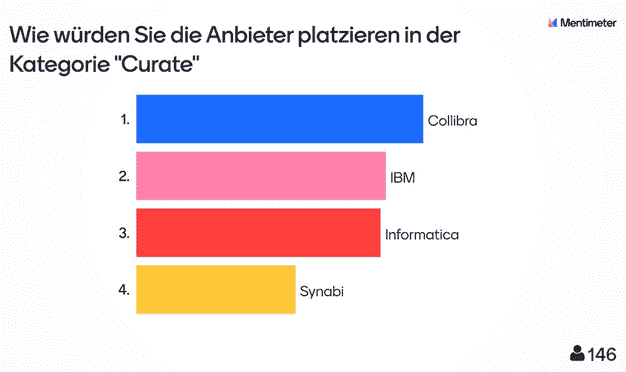
Im Bereich „Curate“ gab es Abweichungen in Methodik und Vorgehen (vgl. IBM im vorherigen Absatz). Gezeigt wurden im Grunde die Datenanbindung und die Verknüpfung technischer Metadaten mit Business Metadaten mithilfe von Machine-Learning-Algorithmen.
Der Prozess der Anreicherung und Aufbereitung weiterer Metadaten (bspw. Metadaten aus Organisation, Prozessen, das Anlegen von Verknüpfungen zwischen Metadaten) kam mir insgesamt etwas zu kurz, so dass es mir nicht möglich war einen Eindruck über die Hilfestellung der Werkzeuge in diesem zeitaufwändigen Curate-Prozess zu gewinnen. Es wurde aber einiges geboten und Highlights gezeigt.
Collibra zeigte bspw. einen „Guided Stewardship Workflow“, in dem anhand eines geführten Workflows Verknüpfungen zwischen fachlichen und technischen Metadaten gemacht werden konnten.
Informatica verwies auf ihre weitreichende Datenmanagementexpertise mit zusätzlichen Funktionen wie Similarity Analysen, die es ermöglichen, Dupletten in den Metadaten zu identifizieren und aufzulösen.
IBM verbrachte „gefühlt“ die meiste Zeit der Präsentation mit dem Thema Kuratierung und zeigte Datenaufbereitung in unterschiedlichen Facetten von der Datenanbindung, über Datenqualitätsanalysen bis hin zur Datenaufbereitung.
Synabi demonstrierte die Erfassung von Metadaten mithilfe vorgefertigter Objekte wie Tags oder Verweisen, die in vorgefertigten Masken genutzt werden konnten.
Mit Ausnahme von Synabi sahen alle Anbieter ML als eine wesentliche Funktion im Bereich Curation.
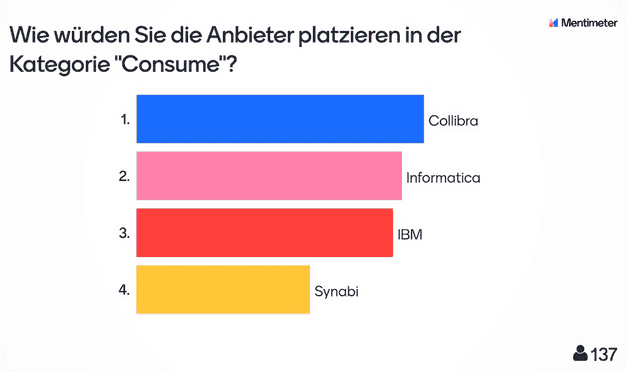
Im Bereich Consume zeigten alle Anbieter einfache und leicht zu bedienende Suchfunktionen und vergleichbare Ergebnislisten. Die drei großen Anbieter zeigten zudem zusätzliche Funktionen, um die Ergebnismenge schneller eingrenzen zu können. Neben Filtern sahen wir Funktionen für Rating, Zertifizierung und weiteres.
Spannend bei Collibra war der Einstieg über die kleine Desktop-Applikation „Collibra Everywhere“ – ein einfaches Suchfenster (aufrufbar aus der alltäglichen Arbeitsumgebung), das schnell erste Fragen beantwortet, bevor dann detailliertere Analysen in der Plattform vorgenommen werden können.
Bei Informatica fielen vor allem die Fein-Granularität der Filtermöglichkeiten auf, die es ermöglichen, die Ergebnismengen aus einer Datenmenge in alle Richtungen einzugrenzen. Zudem wurden bei Informatica und bei IBM auch kurz Instrumente zur Visualisierung von Beziehungen zwischen Objekten vorgestellt, die bei der Navigation und Analyse unterstützen.
IBM ging in seiner Präsentation insbesondere auch auf Berechtigungen ein und demonstrierte, inwieweit sich Sichten auf Metadaten steuern lassen.
Bei Synabi sahen wir die Möglichkeit zur Voransicht auf Berichte zur besseren Orientierung des Nutzers.
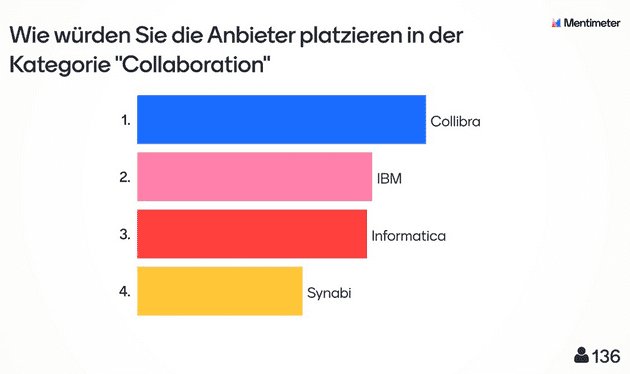
Der Bereich Collaborate lässt sich schwer abgrenzen und zog sich bei allen Herstellern durch die gesamte Präsentation.
Collibra machte insbesondere bei der Vorstellung ihrer Shopping-Basket-Funktion darauf aufmerksam, dass dieser in einem Approval-Prozess endete.
Informatica zeigte darüber hinaus, dass aus unterschiedlichen Positionen im Werkzeug Kommunikationspfade wie Benachrichtigungen genutzt werden konnten.
IBM vertiefte an der Stelle nochmals das Thema Sicherheit und zeigte Konzepte, seine Datenlandschaft in mehreren Katalogen zu strukturieren, eigene Workflows zu gestalten oder aber auch Daten zu schützen.
Synabi ging auf das Thema mit einem Approval-Prozess ein.
Insgesamt ist mein Eindruck, dass wir gute Einblicke sowie eine erste Idee von den Werkzeugen erhalten haben.
Das Webinar war eine tolle Session. Danke an mein Kernteam und danke an die Sprecher von Collibra, IBM, Informatica und Synabi.
Haben Sie Lust auf mehr bekommen? Gerne können Sie sich auch noch die komplette Aufzeichnung anschauen und sich ihr eigenes Bild machen. Über ein Feedback und Ihren Kommentar würde ich mich freuen. Hier gelangen Sie zur Aufzeichnung.
Sie möchten mehr Informationen zum Thema Data Cataloging haben und stellen sich Fragen wie: Welches Werkzeug ist das richtige für mich? Worauf muss ich bei Einführung und Betrieb achten? Wie kann ich mich dem Thema nähern? Oder benötigen Sie einfach einen fundierten Überblick, um Datenkataloge für sich bewerten zu können? Dann empfehle ich Ihnen, sich unsere Angebote zu Data Cataloging „Das 1×1 des Data Cataloging“ als Seminar oder individuell gestalteter Workshop anzusehen. Sprechen Sie uns an.











